Exploitation de compte-rendus médicaux grâce aux word embeddings
2020-06-29



Word Embeddings
- Représentation dense des mots
- Vecteurs de nombres réels
- Dimension indépendante de la taille du vocabulaire
- Proximité dans l'espace vectoriel corrélée à la similarité sémantique
| mots | 0 | 1 | |
|---|---|---|---|
| 0 | asthme | 0.888 | 0.014 |
| 1 | colique | 0.017 | 1.500 |
| 2 | intestinale | -0.420 | 1.880 |
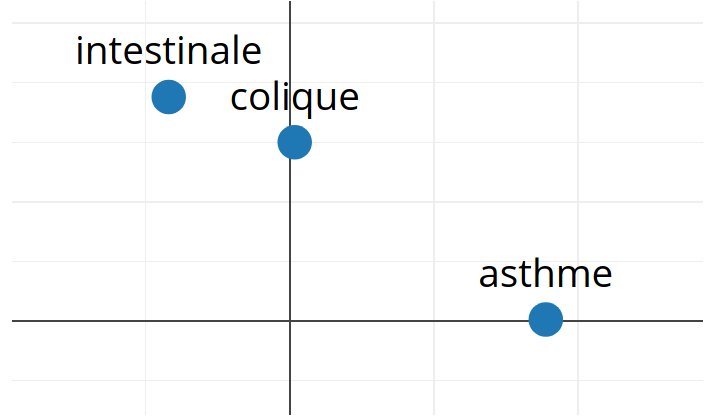
Word Embeddings
Les Embeddings permettent d'utiliser le calcul vectoriel pour effectuer des transformations sémantiques
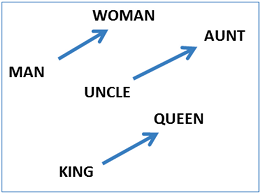
King + (Woman - Man) = Queen
Mikolov, Tomas; et al. (2013). Efficient Estimation of Word Representations in Vector Space↩︎
Pennington, Jeffrey, et al. “Glove: Global Vectors for Word Representation.”↩︎
Le, Q. V. & Mikolov, T. "Distributed Representations of Sentences and Documents"↩︎
Bojanowski, Piotr, et al. "Enriching Word Vectors with Subword Information."↩︎
Peters, Matthew E., et al. "Deep Contextualized Word Representations."↩︎
Devlin, Jacob, et al. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.”↩︎
Akbik, A.; Blythe, D. & Vollgraf, R. Contextual string embeddings for sequence labeling↩︎
Lan, Zhenzhong, et al. “ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations.”↩︎
Biobert : pre-trained biomedical language representation model for biomedical text mining↩︎
Camembert : a tasty french language model↩︎